梯度消失和梯度爆炸问题
网络训练 人工智能
理论上,深度学习中更深的结构会带来更好的结果,因为网络层可以什么都不做。但实际实践中反而适得其反,而这里的矛盾,就要从梯度消失和爆炸谈起。
简介
在深度学习时代,一个更深层复杂的网络结构在理论上应当得到更好的结果,因为网络层可以什么都不做,也就是说深层网络应当至少比浅层网络有更好的性能。但是,在实际实践中,我们会发现网络的加深有时反而会导致性能的下降。导致问题的原因就是梯度消失/爆炸。
什么是梯度爆炸/消失
在训练深度神经网络的时候,我们会使用梯度下降和反向传播的算法。具体来说,我们通过从最后一层向第一层遍历网络,计算偏导。利用链式法则,更加深层的梯度值会经过更加多次的矩阵乘法。
例如,在一个有 个隐藏层的网络, 个导数会乘在一起。如果导数较大,那么梯度在层层反向传播的过程中就会指数级上升,最终导致梯度过大,也就是我们所说的梯度爆炸。反之,如果导数较小,那么在反向传播的过程中,梯度就会指数级减少,最终导致梯度消失。
梯度爆炸/消失的后果
梯度爆炸会导致模型权重参数变化很大,导致整个网络十分不稳定,最坏情况会直接导致权重值溢出(NaN)。梯度消失会导致模型失去学习的能力,无法有效地更新权重,最坏情况会直接导致梯度归零,模型停滞。
如何发现梯度爆炸/消失
我们可以通过观察如下现象来判断模型是否面临梯度爆炸/消失的问题:
梯度爆炸
-
模型没有从训练数据学到很多,导致 loss 没有很好下降
-
模型的 loss 值在每次更新中剧烈变化,很不稳定
-
模型的 loss 值在训练过程中变成 NaN
-
模型权重在训练过程中指数上升
-
模型权重在训练阶段变为 NaN
梯度消失
- 模型提升很慢,甚至早早停止了训练,更多的训练也不会再改进模型
- 离 输出层 近的层权重改变更多,离 输入层 近的层权重改变更小
- 模型权重指数下降,变得很小
- 模型权重变为零
如何缓解梯度爆炸/消失
减少层数
减少层数是一个很直观的解决方法,但是同时也会导致模型更简单,从而没有能力用更复杂的映射解决更复杂的问题。
梯度裁剪(Gradient Clipping)
用于解决梯度爆炸,有如下两种:
-
确定一个范围,如果参数的梯度超过该范围,就裁剪为范围上限。例如,若 clip_value 为 1,这一轮计算的权重为 120,那么我们直接裁剪为 1。
-
根据若干参数的梯度组成向量的 L2 范数进行裁剪。具体来说,如果在某一次反向传播中,假设各个参数的向量为:
我们计算它的 L2 范数
LNorm:再设置
clip_norm,如果 ,则对权重向量 乘上缩放因子 scaling:那么梯度消失能不能用这种 scaling 的方法来解决呢?
-
有人说可以,只是现实中往往用更好用的自适应学习率、LSTM/GRU 等方法;
-
也有人说不行,因为无法区分梯度小是因为梯度消失,还是因为接近局部最小值;
-
也有反对者提出,在梯度很小的时候,它的方向就不像梯度爆炸时那么明确,那么 scaling 并不一定能够让模型在正确的方向改进。
笔者觉得都说得有道理。。。还希望有大神能够指点。
-
初始化权重(Weight Initialization)
从该博客中可知,权重初始化过大(过小)很可能导致梯度爆炸(消失)。在反向传播过程的矩阵乘法中,每层的方差不断累积导致最终方差过大(过小),导致梯度爆炸(消失)。因此,可以利用 Xavier 初始化或者 Kaiming 初始化等方法来解决这一问题。
Xavier & Kaiming Initialization 日后补齐…
更换激活函数
例如,常用的激活函数 sigmoid 为:
在反向传播中对其求导可得:
我们绘制 的图像在区间 的情况:
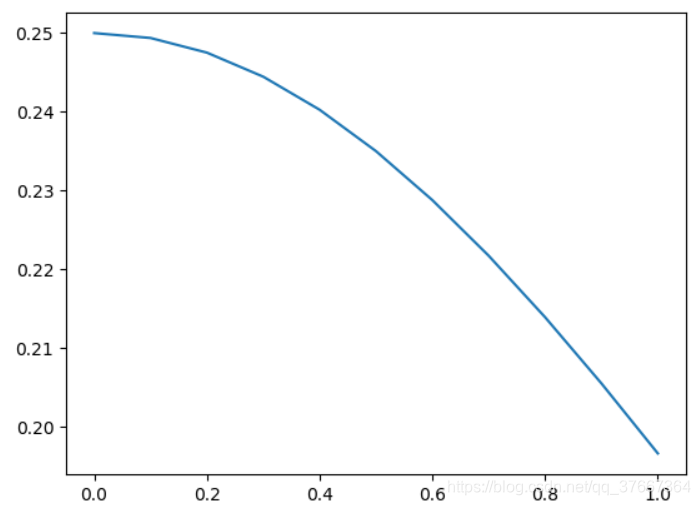
我们发现 的取值大概在 之间,也就是说,在反向传播的过程中,梯度值会不断缩小 4 倍到 5 倍,最终使得接近输入层的网络层参数几乎不被更新,无法进行后续训练。将 sigmoid 更换为 ReLU 等可能可以缓解这一问题。
权重正则化
目标函数 = 损失函数 + 正则化项,通过在目标函数中加入正则化项,来惩罚更大的权重,从而使得权重不会过大,达到缓解梯度爆炸的效果。
批标准化(Batch Normalization)
一些激活函数,如 sigmoid,我们发现在输入(绝对值)偏大的时候,激活函数对输入的敏感度很低(可能输入10和100没什么差别),而对输入区间在靠近零的值更为敏感。因此,批标准化(BN 层)通过标准化输入的模值,使其更靠近中间的区间,这样可以使激活函数效果更明显。这种对输入模值的控制,也很好地解决了梯度消失/梯度爆炸的情况。
上述解决方法其实每一个都值得用一整篇文章来深入讨论,奈何笔者精力有限,这里只能粗浅地讨论这些问题,期待自己笔耕不辍,在未来慢慢填补这些空白。
总结
梯度爆炸和梯度消失的问题曾困扰着深度学习的推进,但如今已经有很多的解决方法,也不再是一个棘手的问题。与此同时,深度学习效果不佳的原因有很多,梯度爆炸和消失并不是所有原因的罪魁祸首,还有诸如调参、网络结构和退化层面的问题……因此,要有足够的经验和牢固的知识体系,才能够更高效地发现问题和解决问题。