LLM推理加速 Lesson 1:Roofline模型
大语言模型 推理加速
加入新工作后主攻LLM推理加速这一领域,我希望系统地记录学习和实践结论。作为第一篇文章,我选择首先Roofline模型。它来源于2009年伯克利发表的文章 Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures。我认为它是LLM推理加速中最为基础和本质的概念之一,可以很好地串联后续加速研究。
1. 推理速度的两大限制:算力 & 带宽
1.1 计算平台相关指标
算力: 指一个计算平台的性能上限,是每秒能够完成的最大浮点运算数,单位是FLOPS。
带宽: 指一个计算平台的带宽上限,是每秒能完成的最大内存交换量,单位是Byte/s。
最大计算强度: 描述的是一个计算平台上,单位内存交换内最多用来进行多少次计算,单位是FLOPs/Byte。
1.2 模型相关指标:
计算量: 指输入单个样本,模型一次前向传播所发生的浮点运算次数,单位是FLOPs。
访存量: 指输入单个样本,模型一次前向传播过程中发生的内存交换总量,单位是Byte。
模型计算强度: ,描述一个模型每Byte交换用于进行多少次浮点运算,单位是FLOPs/Byte。
2. Roofline模型
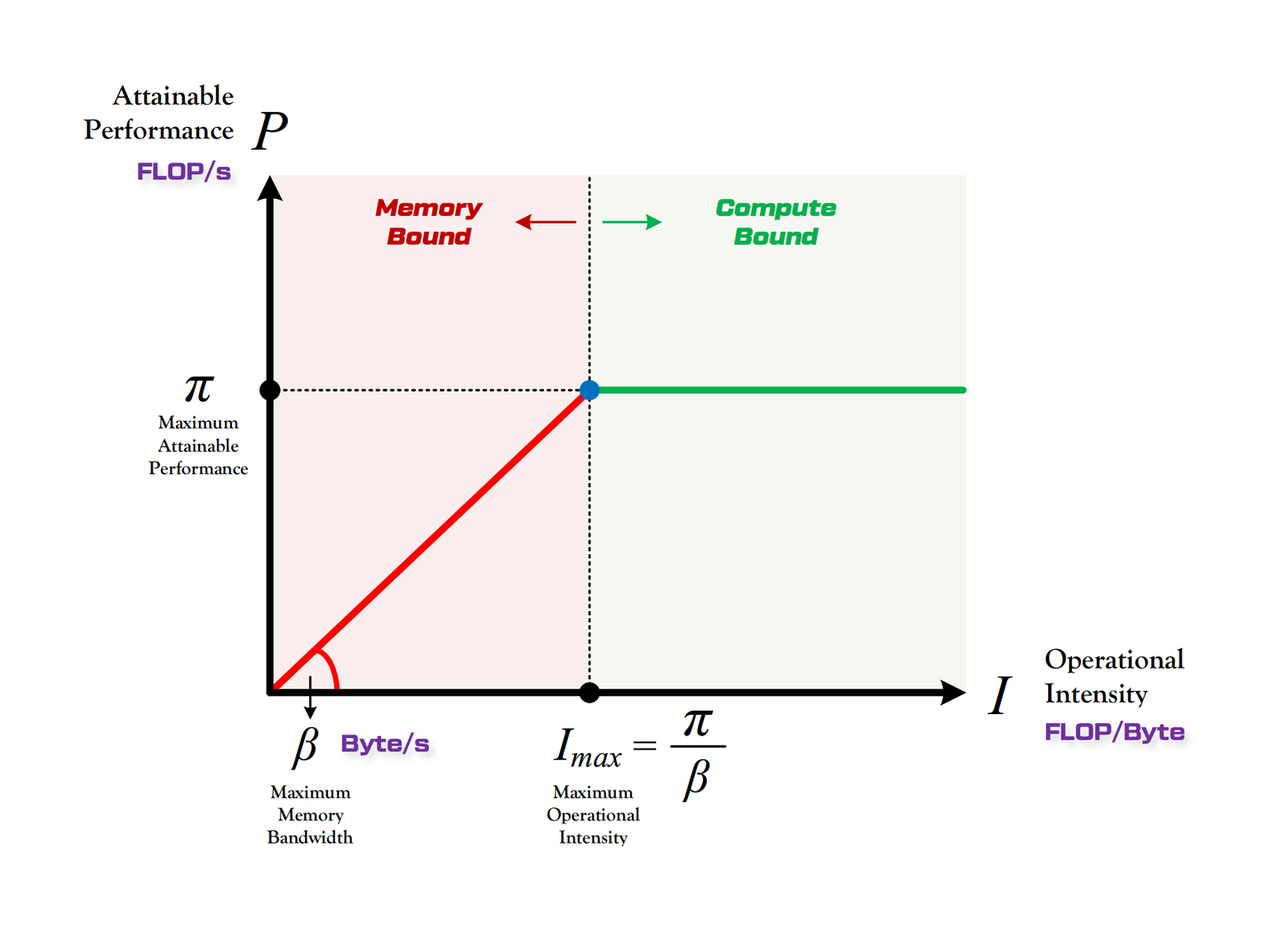
Roofline模型描述的是:模型在一个计算平台的算力和带宽限制下,能够达到多快的浮点计算速度。它所绘制的“计算强度-计算速度”曲线如下图所示:
 所谓Roofline,就是指计算平台的“带宽”和“算力”共同构成了限制模型推理速度的“天花板”。Roofline曲线图划分出两个瓶颈区域:
所谓Roofline,就是指计算平台的“带宽”和“算力”共同构成了限制模型推理速度的“天花板”。Roofline曲线图划分出两个瓶颈区域:

2.1 计算瓶颈区域:Compute-Bound
当模型的计算强度大于计算平台的最大计算强度时,就会处于Compute-Bound的状态(图中绿色部分)。此时代表着模型已经利用了计算平台100%的算力。换言之,我们优化LLM推理加速的终极目标就是:让模型推理进入Compute-Bound的状态。
2.2 带宽瓶颈区域:Memory-Bound
当模型的计算强度小于计算平台的时,此时模型处于Memory-Bound的状态。其实用Momory-Bandwidth-Bound表述更贴切,因为这不是显存内存大小带来的限制,而是由访存速度带来的限制。这一区域中,曲线的斜率等于带宽。若一个模型推理时处于Memory-Bound状态,那代表它无法充分利用平台算力,需要通过优化来尽可能达到Compute-Bound。
2.3 LLM与Roofline模型
那么,LLM和Roofline模型之间的关系是什么呢?LLM的推理过程分为prefill阶段和decode阶段:
- Prefill阶段:LLM对输入prompt的所有tokens计算QKV,到生成第一个回答token。由于每个token的计算是独立的,因此可以并行。由于prefill中的大矩阵相乘操作(QKV)计算慢读写快,因此是一个compute-bound的操作。
- Decode阶段:LLM自回归地根据前置tokens,依次生成新的回答tokens。由于这种前置依赖性,decode的过程只能串行生成。通常将前置tokens的KV值保存为KV Cache,以实现复用,空间换时间,减少计算复杂度。在KV Cache的帮助下,decode过程每次只需要用上一个token的q,和之前的KV相乘,计算量大幅降低,但是decode需要一步一步反复调用,因此是一个memory-bound的操作。
3. 优化策略
针对大模型推理场景,我们速度优化的目标是:在更少的内存操作下,完成更多的浮点运算。具体有如下方法:
- 增大batch size,增加计算强度。增加batch size可选择如下方式:
- 减少KV Cache,比如采用Multi-query attention和Grouped-query attention;
- 采用Paged Attention在系统层级减少KV Cache的内存碎片;
- 量化压缩模型,减少内存消耗,增大batch size(权重量化,KV Cache量化);
- Continuous batching 也是一种充分利用批量推理的优化。
- 投机采样:借助小模型(draft model)多次采样+大模型一次验证的方式,让大模型每个step可以并行推理多个tokens,从而增加计算强度;
- 减少内存操作次数,可选方案有:
- 算法优化:比如Online Softmax;
- Kernel fusion: 经过内核融合(算子融合/层融合),一次性进行多个算子的计算,避免中间结果在HBM(global memory)到SRAM的反复读写带来额外开销。
4. 总结
本文介绍了Roofline模型以及如何用它来指导LLM推理的加速优化。本文一个核心点在于,判断一个模型的推理在特定计算平台上是否还有加速空间,需要判断其在Roofline曲线上的位置。如果还处于Memory-Bound,那么可以采用增大batch,投机采样等方案继续优化;如果已经位于Compute-Bound,那么常规优化将难以带来收益,只能考虑低精度、算子融合或硬件升级等方案降低模型算力要求,再进一步优化。
此外,Roofline模型本身假设模型计算强度相对固定,并忽略了缓存层级与通信开销等,因此在实际LLM推理中,还需结合性能分析工具获取更全面的信息,避免仅凭曲线做判断。
Reference:
https://blog.csdn.net/daihaoguang/article/details/143671796 https://zhuanlan.zhihu.com/p/34204282