LLM推理加速 Lesson2:FlashAttention
大语言模型 推理加速
FlashAttention来自斯坦福团队于2022年发表的FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。和我们之前Lesson1中的Roofline模型相呼应,它正是从Memory-Bound的角度,减少了Transformer在自回归生成中的访存开销,缓解IO以实现提速。实验证明FlashAttention能够保证无损的前提下,将BERT-large提速15%,GPT2(序列长度1k)达到3倍速度。
1. 从IO的角度思考优化
近年来,GPUs计算速度(FLOPS)的提升,要快于访存速度的提升。然而,就算计算速度再快,如果数据没来得及准备好,那也无济于事。这也是为什么当前很多加速工作,由于忽视了IO的影响而仅专注于减少FLOPs,在实际场景中无法有效提速。
总之,只有计算速度和访存速度二者相平衡,才能实现有效的加速。鉴于当前GPU平台上二者的错配问题,我们需要在软件层面来补偿使其平衡。
2. Attention计算的Memory-Bound特性
在LLM推理加速Lesson1中,我们介绍了Memory-Bound和Compute-Bound。此处我们总结一些算子的特性:
- Compute-Bound:矩阵乘法
- Memory-Bound:Element-wise操作,主要包括:
- 激活函数、Dropout层,Masking操作;
- 归一化操作:Softmax,LayerNorm,Sum。
而Transformer的主要模块Attention包含了大量的element-wise计算,是一个Memory-Bound的操作,如下图所示:

即便绝大部分的FLOPs计算来自于矩阵乘法Matmul,但是Attention的大部分latency还是来自于IO。
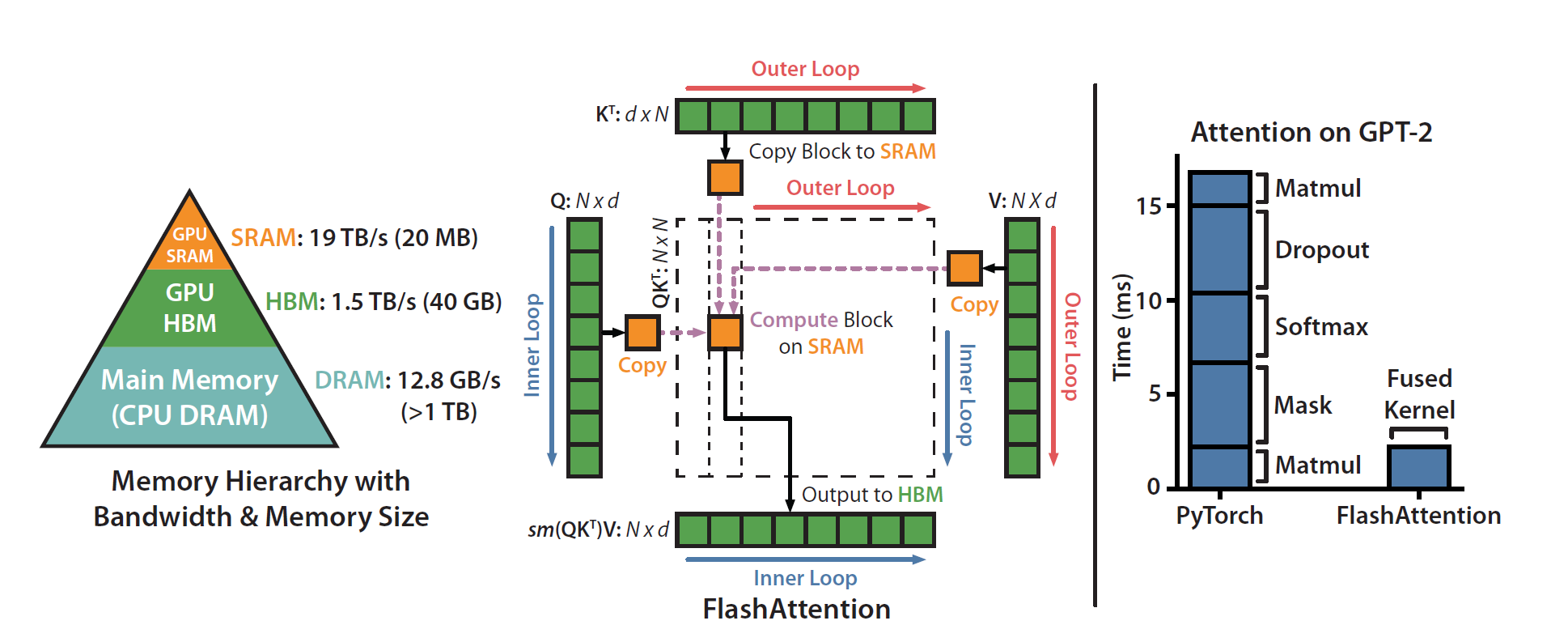
3. FlashAttention的动机:内存层级结构
计算平台的内存不是一个单一整体,而是一个层级结构,并且遵循一个通用的规律:速度越快的memory,价格越贵且存储空间越小。示意图如下所示:

为了方便理解,我们以A100为例(别的GPUs的内存层级比例也基本一致):
- DRAM(HBM):A100拥有40~80GB的high bandwidth memory(HBM,也就是我们常说的显存),带宽为1.5~2.0TB/s;
- SRAM:A100拥有108个流式多核处理器,每个处理器的片上SRAM大小为192KB,带宽可达19TB/s。
Attention计算的访存&计算流程伪代码如下:

可以看到,传统的Attention实现包含了多次的大矩阵访存,这是Attention计算的主要瓶颈。针对这一问题,FlashAttention的解决方案为:
- 算子融合(Kernel Fusion):把 融合为一个或两个kernel,减少中间结果反复读写全局DRAM的开销;
- 分块思想(Tiling):将N个Query分成若干个Block,对每个Query Block中,对Key,Value再分为多个更小的Block。这样做能够让Attention计算在存储空间很小的SRAM上完成,得到最终输出后才会写回全局DRAM,将DRAM的读写量从降到。
其完整的伪代码如下:

本文更多探讨设计的思考以及总体认识,如果需要了解代码实现细节,以及理论证明,可以关注博客 ELI5: FlashAttention以及原论文。
4. 总结
一句话总结,FlashAttention关注到了Attention计算的Memory-Bound特性,通过算子融合以及分块的思想,充分利用内存的层级结构,将Attention的计算过程限制在SRAM中完成,大幅减少了访存全局DRAM的次数,从而实现提速。
除了本身的提速效果,FlashAttention工作的另一价值,是将算法优化的视角,从单纯的减少计算量,转移到更全局系统的IO层面。因此做加速一定要关注限制速度的真正bottleneck是什么,才能对症下药,让加速工作立竿见影。