今天学习RNN
人工智能 神经网络
如何处理序列型数据?RNN!
循环神经网络
我在实际应用中,我们会遇到很多序列型的数据:
- 自然语言处理中: 可以看作第一个单词, 可以看作第二个单词,以此类推。
- 语音处理: 是每帧的声音信号。
- 时间序列问题:每天的股票价格、每天的商品价格等。
对于序列型数据,原始的神经网络无法处理,因此我们引入 RNN 对序列问题进行建模。RNN 引入了隐状态 (hidden state)的概念, 可以对序列型数据提取特征后再转换为输出,如下图从 开始。

接着向前一步到 。注意每一步中的参数 ,, 是共享的,这是 RNN 的重要特点。

不断地向前移步,我们可以处理整个序列。之后我们需要输出,输出的方法就是直接通过 进行计算:

RNN 变体结构
经典 RNN:
经典 RNN 对于序列的每一个值 都输出一个 ,这意味着输入和输出序列必须等长。这种经典 RNN 可以利用在:
- 计算视频每一帧的分类标签。
- 输入字符,输出为下一个字符的概率。详见 Char RNN
但是输入输出等长(NN)这一限制很大程度局限了 RNN 的作用,因此 RNN 出现了很多变体。
有时候,我们需要处理的问题是输入一个序列,输出一个单独的值。这种情况下,我们可以只在最后一个 上进行输出变换即可。

这种结构常用于处理序列分类的问题,例如:
- 输入一段文字,判断其文学类别
- 输入一段音乐,判断其艺术风格
- 输入一段语音,判断其情感倾向
如果我们需要输入一个值,然后输出一串序列,我们有两种实现结构:
只在序列开始进行输入计算

把输入信息作为每个阶段的输入

这种 1 N 的结构可以处理的任务有:
- 从图像生成文字(image caption)
- 从类别生成语音或者音乐
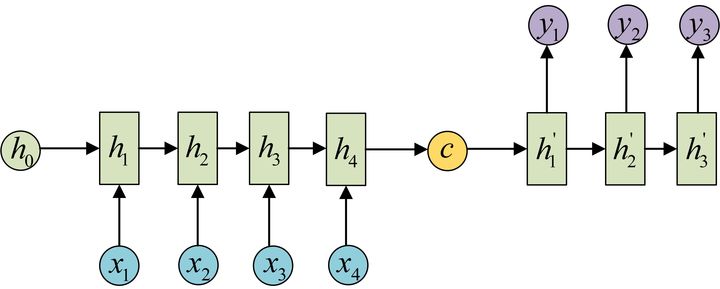
是 RNN 最重要的一个变种。这种结构又被称为编码器-解码器(Encoder-Decoder)模型,或者称为 Seq2Seq 模型。
Encoder-Decoder 结构将 RNN 拆解为编码器和解码器两个部分。编码器部分将输入数据编码成一个上下文向量 :

得到 的方式很多,上图展示的是最简单的方法:将编码器的最后一个隐状态赋值给 。还可以对左后的隐状态做一个变换得到 ,也可以对所有隐状态做变换。
得到编码 后,我们用另一个 RNN 进行解码,这个 RNN 称为解码器。具体做法是将 作为初始状态 输入到解码器中:

或者我们也可以将 作为每一步的输入:

编码器-解码器结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译:编码器-解码器最经典的应用,事实上这一结构就是在机器翻译领域率先提出的。
- 文本摘要:输入一段文本序列,输出这段文本序列的摘要序列。
- 阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- 语音识别:输入是语音信号序列,输出是文字序列。
总结
本文大致讲解了 RNN 的原理、变体以及对应的应用领域。RNN 充分考虑了序列型数据中每个数据之间的相关性,而不是独立地考虑数据,从而能够更好的处理序列信息。
参考博客: