论文学习: SongMASS
生成模型 音乐 人工智能
人工智能根据歌词生成歌曲,厉害吧~
人工智能歌曲创作近年来十分火热,其中基于旋律的歌词生成和基于歌词的旋律生成时歌曲创作中最重要的两个任务,都可以视为标准的“序列到序列”生成。该方向的研究工作有以下两个挑战:
-
标注好的歌词-旋律配对数据非常缺乏
由于歌词信息和旋律信息实际上只具有弱相关性,因此需要大量标注的歌词-旋律配对数据来训练并寻找弱相关性。过去的工作大多只利用了有限的配对数据来训练,而没有利用大量的无标注非配对歌词和旋律数据。
-
生成歌词和旋律之后,如何生成歌词与旋律的对齐信息很重要
在歌曲中,每个音节必须严格对应一个或多个音符。过去大部分工作没有考虑到对齐,或者采用固定模板来控制对齐,而限制了歌词和旋律生成的多样性。
因此,本文提出 SongMASS 方法来解决问题。
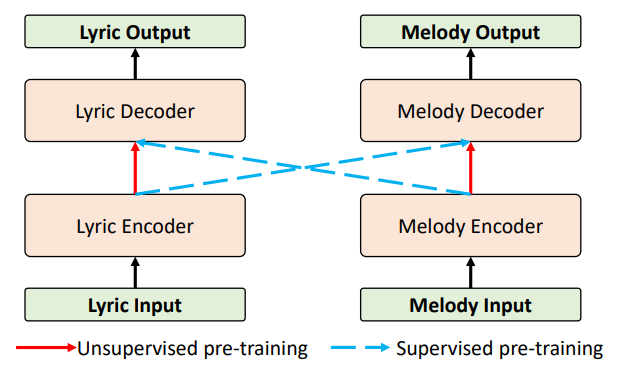
SongMASS 采用了编码器-解码器(Encoder-Decoder)的框架,并且提出了一种针对歌曲的序列到序列学习和对齐约束。由于歌词和旋律之间的差异性较大,研究员们对各个模态(歌词属于文本序列,旋律属于音符序列)分别使用了单独的编码器和解码器。对于相同模态的编码器和解码器,研究员们使用了基于掩码的序列到序列学习(Masked Sequence-to-Sequence Learning)来学习无标签数据的知识。对于不同模态的编码器和解码器,他们则在标记好的歌词-旋律配对数据上,使用标准的序列到序列学习,来拉近不同模态之间的语义距离。

由于一首歌的长度较长,通常由多句话构成。因此,在相同模态的预训练过程中可以采用句子级的掩码策略(在每句内分别使用基于掩码的序列到序列学习)来学习歌词或者旋律的表征。掩码的设计如图所示。

同时,为了能够学习到歌词与旋律的对齐语义,研究员们又在监督数据的训练上添加了句子级和单词级的注意力约束,限制每句歌词只能对齐到对应的旋律上来确保句子级上的约束。其设计如图所示。

而在单词级上,研究员则希望每个单词 和对应的音符 之间的注意力权重最大。而这个期望权重设置如下:
其中, 代表句子的长度。在预测的过程中提取出每个单词和旋律的注意力权重,并用一种动态规划的思路来获得歌词与旋律之间的对齐。
研究员们在 LMD 数据集上对方法进行了验证,实验结果如下图所示。
